
2019年3月1日 这一天面试了4家公司
面试原因: 主要是在公司太安逸了, 不知道外面世界有什么变化, 听说今年是互联网寒冬, 我去前面探探路.
总结: 1. 千万不要一上午面试2家公司. 时间来不急,没工夫吃饭,影响下午发挥,导航费电快,还要挨个与人事说我延迟了 2. 自身知识点不够深入, 总想获得太多, 结果是太多都做不到手到擒来.
计划
上午10点 每日一淘 (每日优鲜旗下的公司目前B轮,安排到供应链系统)
上午11点30 信必优 (外包公司,安排到龙湖地产的生产制造系统)
下午14点 松果出行 (做共享车的,安排到物联网或供应链系统)
下午16点 克莱特 (外包公司,安排到项目leader)
晚上19点30 天猫事业部二面 (阿里巴巴供应链)
结果
每日一淘 (回家等回复)
技术面试官认为技术不达标. 人事说回家等回复
信必优 (通过)
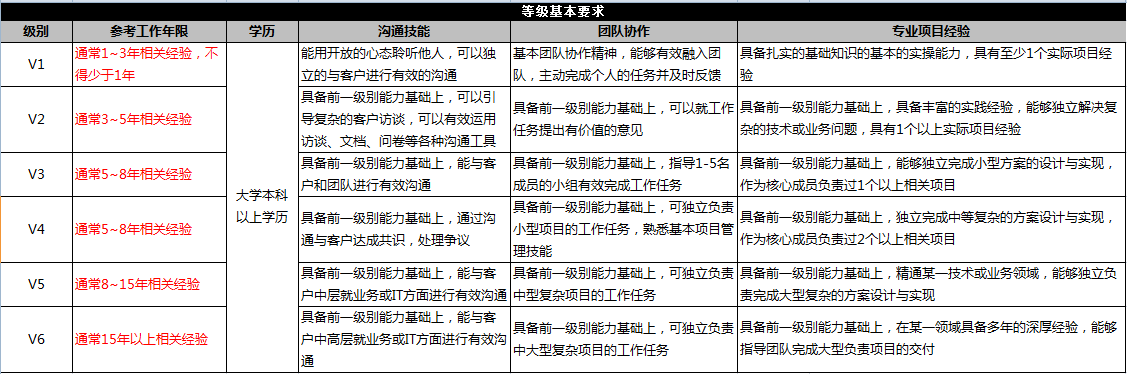
当场给了offer, 我被定到了V3级别,
我觉得是外包公司, 不值当. 想等等阿里巴巴的面试结果
(下图是级别定义)
松果出行 (回家等回复)
面试官是负责物联网的, 原本好像想让我跟他项目组, 后来觉得我不行, 我也觉得我确实不行,
问我java虚拟机,我只回答了堆空间, 但别的都没有逻辑性的描述出来,
问我设计模式与设计原则, 我给忘了,
问我介绍MQTT, 我没有逻辑性的回答,东一片西一片,
问我最近看过哪些书, 我就记得的HTTP权威指南, 别的也忘了
虽然平时虽然看过或用过,但是大部分都记不住或描述不出来.这些软知识要背会,不能忘记.
后来推荐我换供应链项目组. 技术说回家等回复
(下图是松果出行的面试题)
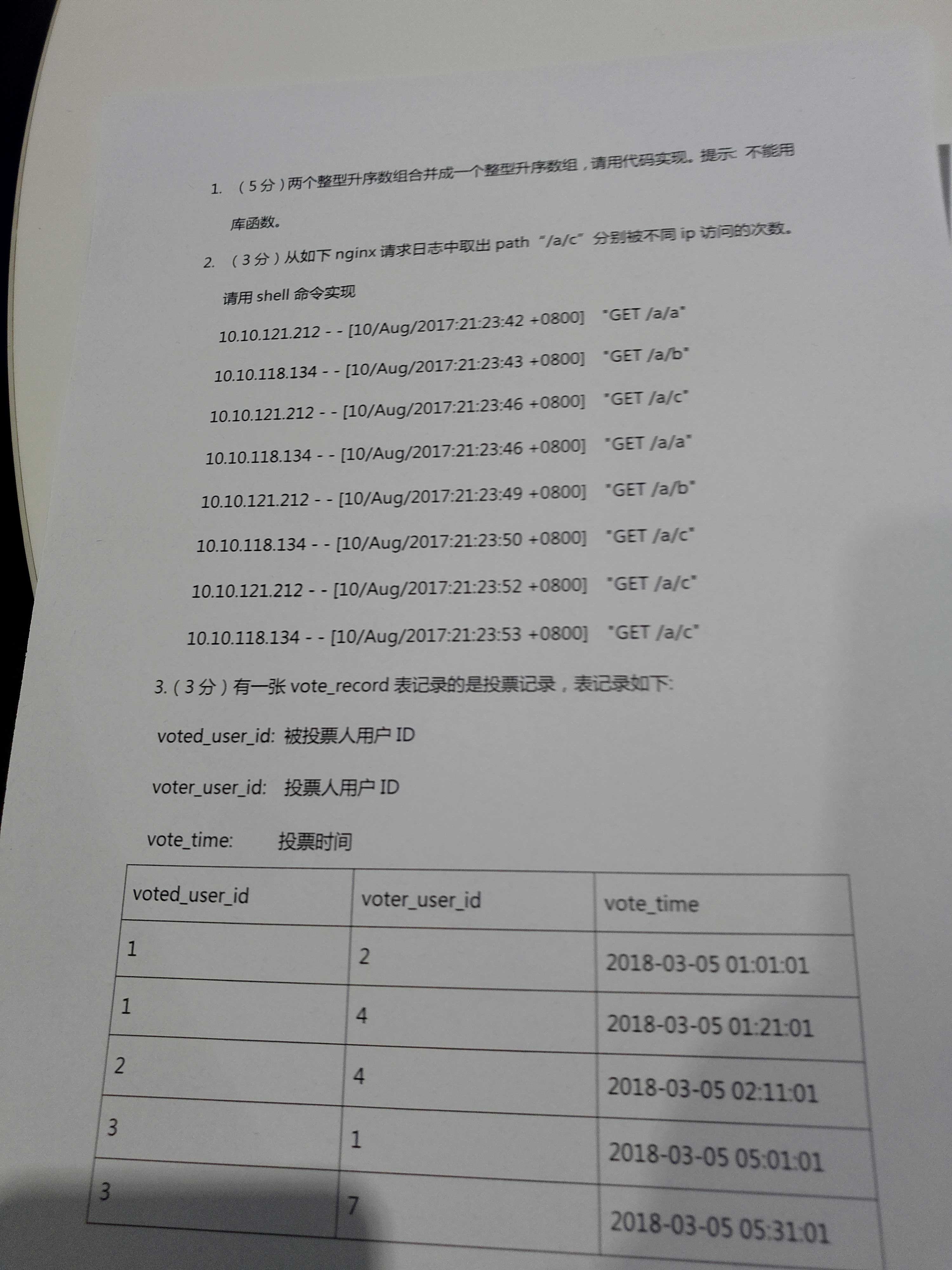
松果出行的面试题 - 第一题
/**
* 合并从小到大的有序数组
* @param args args
*/
public static void main(String[] args) {
int[] array2 = {1,2,5,9,61,80};
int[] array1 = {3,5,7,10,12,19,22,33};
int[] result = merge(array1,array2);
System.out.println(Arrays.toString(result)); //输出结果为[1, 2, 3, 5, 5, 7, 9, 10, 12, 19, 22, 33, 61, 80, 0]
}
public static int[] merge(int[] array1,int[] array2){
int[] result = new int[array1.length + array2.length +1 ];//留最后一位用作交换位置
for(int i=0; i< array1.length; i++){
result[i] = array1[i];
}
for(int i=0; i< array2.length; i++){
int array2Number = array2[i];
int resultCurrentIndex = array1.length + i;
int maxNumber = array1[array1.length -1];
if(maxNumber <= array2Number){
result[resultCurrentIndex] = array2[i];
}else {
sort(result,resultCurrentIndex,array2Number);
}
}
return result;
}
private static void sort(int[]result,int resultCurrentIndex,int insertData){
for (int j = 0; j < resultCurrentIndex; j++) {
if (result[j] >= insertData) {
insert(result, j, resultCurrentIndex, insertData);
break;
}
}
}
private static void insert(int[] result,int insertIndex,int endIndex,int insertData){
for(int i= endIndex; i> insertIndex; i--){
result[i] = result[i-1];
}
result[insertIndex] = insertData;
}
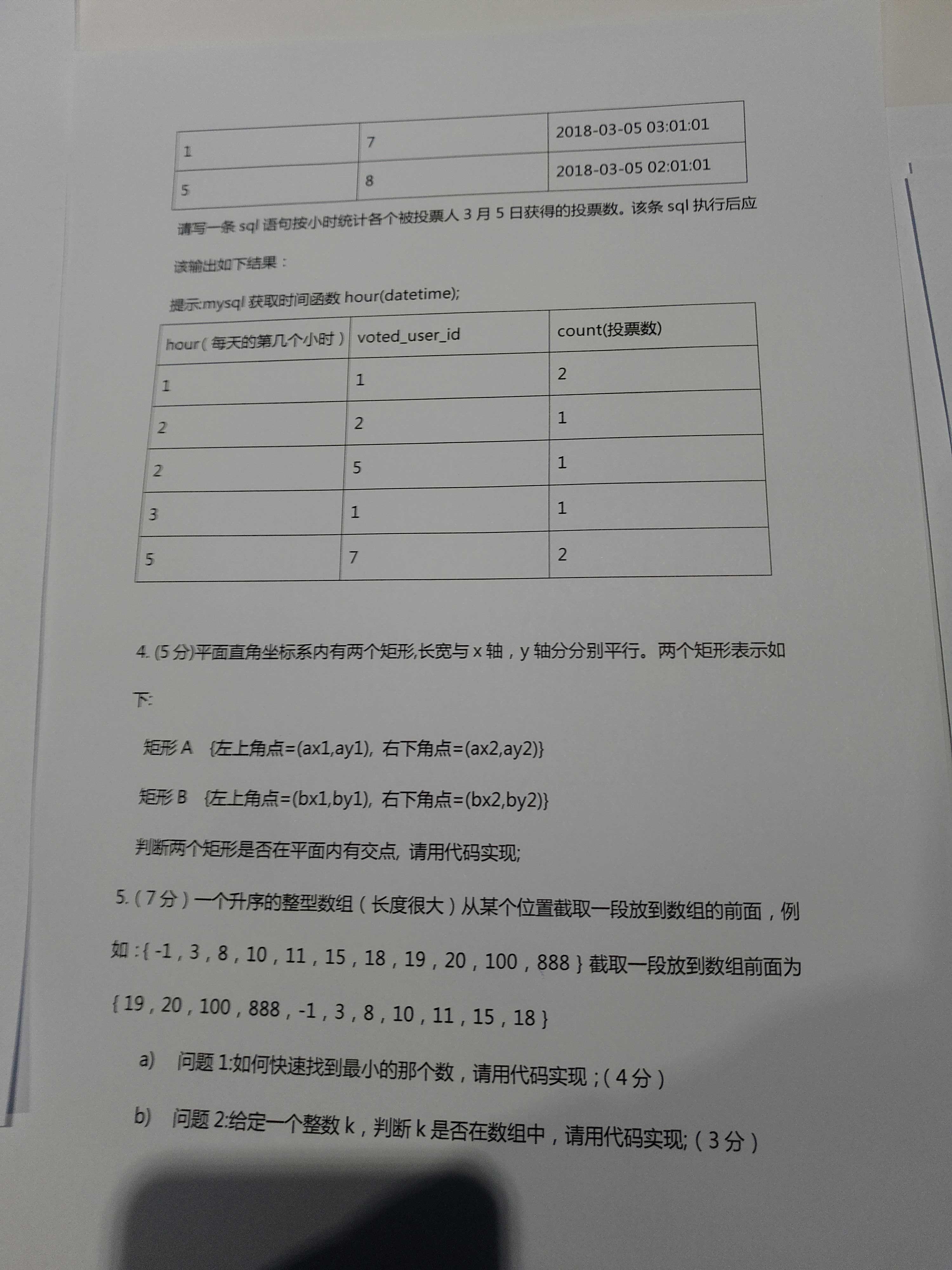
松果出行的面试题 - 第二题答案
grep -w '/a/c' access.log | awk '{print $1}'|sort|uniq -c
匹配 精确等于 /a/c 从access.log文件中找 并且 将空格分割后下标为1的(ip)拼接下标为7的(api地址) 并且 排序令ip相邻 并且 去重 统计
输出结果
1 103.254.69.245
1966 103.254.69.246
10 106.120.24.83
21 106.121.63.124
1 106.2.232.184
1 117.136.38.163
24 119.253.81.240
4 1.202.42.171
1 120.244.112.63
5 124.64.16.217
2 124.64.16.226
2 124.64.16.98
16 175.20.94.226
2 223.104.3.45
273 223.72.89.80
7 223.72.91.48
1 59.108.15.248
1 61.148.243.201
克莱特 (回家等回复)
技术面试官是个女的. 问了问项目, 别的地方就随便问了问,时间很短就20分钟. 技术说回家等回复
天猫事业部二面 (推迟至周一)
我打电话给客服说推迟到下周一19.30,白天太累了, 下午就不在状态了, 周末要好好准备下
笔试题如下
//评测题目: 有一个字符串它的构成是词+空格的组合,如“北京 杭州 杭州 北京”,
//要求输入一个匹配模式(简单的以字符来写), 比如 aabb, 来判断该字符串是否符合该模式,
//举个例子:
//1. pattern = "abba", str="北京 杭州 杭州 北京" 返回 ture
//2. pattern = "aabb", str="北京 杭州 杭州 北京" 返回 false
//3. pattern = "baab", str="北京 杭州 杭州 北京" 返回 ture
private static ThreadLocal<Map> mapThreadLocal1 = ThreadLocal.withInitial(HashMap::new);
private static ThreadLocal<Map> mapThreadLocal2 = ThreadLocal.withInitial(HashMap::new);
public static boolean wordPattern(String pattern, String str) {
if(pattern==null || str == null || str.isEmpty()){
return false;
}
String[] array = str.split(" ");
if(pattern.length() != array.length){
return false;
}
Map map1 = mapThreadLocal1.get();
Map map2 = mapThreadLocal2.get();
boolean result = true;
for(int i=0; i<array.length; i++){
if(map1.put(pattern.charAt(i),i) != map2.put(array[i],i)){
result = false;
break;
}
}
map1.clear();
map2.clear();
return result;
}
下面是4次面试都出现的面试问题
1. 介绍你曾经最熟的项目, 你负责什么
给公司内部做猎头系统, 我是在系统还没开始咋做的时候加入的,到现在已经上线使用4个月了。
有三个基础对象,猎头(员工),客户(通过拜访和关系获取),候选人(通过各个招聘平台和关系获取)。
维护的是客户与候选人关系的订单
生命周期是 1.把候选人推荐给客户,2.安排面试,3.面试反馈,4.offer,5.入职,6.过保,7.猎头分配业绩,8.review复盘
我负责客户的公司,项目,职位搜索。订单生成推荐报告。
加入的时候,公司内用的是第三方猎头系统,叫谷露。新系统上线前要解决平滑迁移的问题, 于是我登陆老系统调研了业务对象,写了个新老系统的业务模型和数据模型差异文档。 需要迁移的有DB和静态文件。 列出了能一次性同步解决的数据和支持实时同步的数据,交给了产品经理,然后产品,技术,人事,业务一起沟通,安排下了过度流程, 局部多阶段迁移,DB的数据我先根据业务模型看了看老系统的表结构,然后我写了个框架, 这个框架由读数据的迭代器和写数据的任务组成,读数据就是分页+id排序丢到写任务里,写到新系统中,并且还支持断点续传和暂停和修改拉取数量,异常重试,ID映射 这样就同时支持了DB的实时同步和一次性同步。 但是还有文件的同步,文件的同步我就直接用shell命令 scp传到新系统的静态目录下了。
过了2个月后,公司开了个子公司,我在母公司,以前已经有一个子公司了,又开了个子公司, 希望把以前子公司的数据同步到新的子公司去,业务和技术也不用付出多少代价老代码复用了, 但是新的子公司不但想要以前子公司数据,还想要母公司的数据,于是我用Canal实现了我那个框架读数据的迭代器, 并且支持Sql重写,Sql的Aop可以在Sql运行过程中加业务逻辑,过滤,改Id,这些都是Canal不支持的,但是业务上需要的。
我搭建了公司的Canal和Elasticsearch(IK + synonym)集群,公司中用Canal一处是给DB用的,一处是给ES用的,这些我都给扩展了一下。
推广落地了Yapi的使用,推广了服务端的开发规范,实现了一套Jenkins生产和预生产和开发环境,测试环境的上线迭代开发流程。 而且我经手的工作都在Wiki上有文档,方便他人接手。 设计了应用对于机器需求和分配结构(生产环境每家公司(一主一备,一个预生产))
2. 你曾经最熟的项目中的对象设计与对象流转
3. 你现在项目中是什么身份
4. 如果给你需求,你怎么设计系统
| 答 |
|---|
| 1. 考虑对外的系统api |
| 2. 收集需求中的对象,按照对象生命周期拆分模块 |
| 3. 定义对象之间的api |
5. 你曾经最熟项目中用到的技术挑着问
6. 挑简历列的技术栈问
7. 数据库优化(类似的问题)
8. linux怎么搜索统计一个日志文件中的数据(类似的问题)
grep -w '/user/list' access.log | awk '{print $1}'|sort|uniq -c
匹配 精确等于 /user/list 从access.log文件中找 并且 将空格分割后下标为1的(ip)拼接下标为7的(api地址) 并且 排序令ip相邻 并且 去重 统计




