
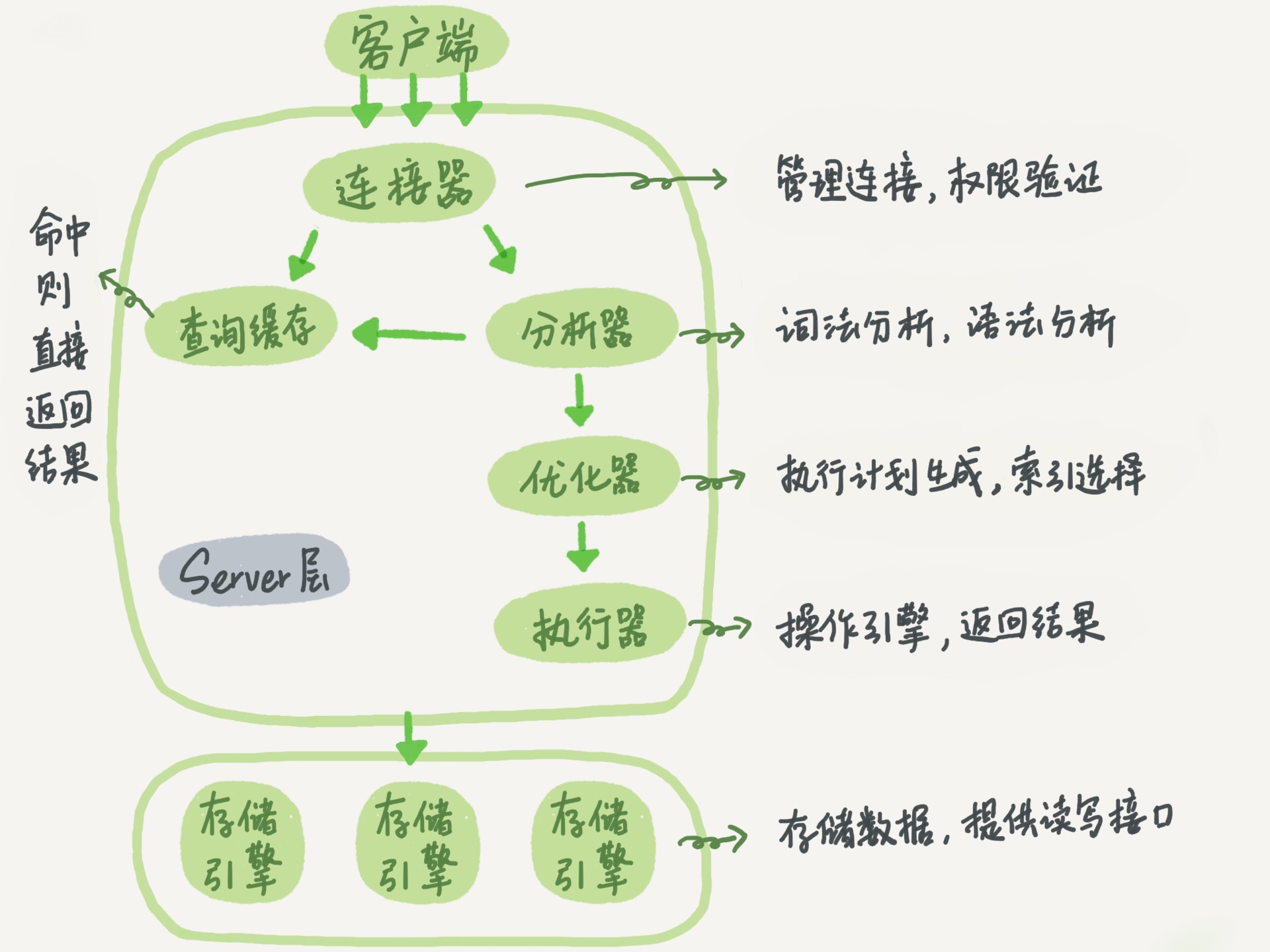
mycat2的目标是成为一个分布式数据系统,数据库系统框图如下
数据库系统绕过了操作系统对文件与内存管理, 对文件块(聚集索引)与内存块(页buffer,join-buffer,网络buffer)统一申请管理.
数据库系统 组合使用了三种文件存储方式管理, 堆结构(扫描查询),Hash结构(等值查询),树结构(范围查询,排序)

mycat2 新特性
-
配置与运行简单,拉取项目main方法直接运行即可用.
-
全局自增主键 (只需要建表语句即可)
-
更少的内存消耗 (代理数据包透传)
-
DSL语言. 类似spark-sql(动态落库的分布式sql处理)
1. DSL语句可以显示的处理mycat-sql的执行流程 显示编程式处理mycat的执行流程, 意味者后端数据库的选择(读写分离,数据分片)更加清晰灵活 2. DSL语句可以用java语言,也可以用HBT语言 -
sql拦截器
1. 需要搭配DSL使用 -
explan改写 (查看分布式执行过程)
explan select * from table;
mycat整体分为如下3部分
-
前端链接器 io.mycat.proxy.handler.MycatHandler
1.处理网络事件 (接入链接, 读, 写, 关闭)
-
分析器 io.mycat.client.MycatClient#analysis(String sql)
确认以下结果
1.哪个目标数据源
2.哪个目标库
3.哪个目标表
4.是否开事物
5.是否分片,分片类型
6.用哪个执行器
-
执行器
1.根据事物级别,建立后端数据库的链接 (两个实现 1.proxy 2.jdbc(xa))
2.增加mycat的sql语法
3.选择数据库的客户端. proxy 或 jdbc
代码: 接口 io.mycat.Command
io.mycat.upondb.MycatDBClientApi (用于实现mycat自己的语法) io.mycat.proxy.handler.BackendNIOHandler io.mycat.MySQLTaskUtil#proxyBackend TransactionSessionUtil
mycat链接器
/**
* mycat客户端
* @author Junwen Chen
**/
public interface MycatClient extends MycatDataContext {
/**
* 分析器, 用于确认以下结果
* 1.哪个目标数据源 2.哪个目标库 3.哪个目标表 4.是否开事物 5.是否分片,分片类型 6.用哪个执行器
*
* mycat整体分为如下3部分
*{@link MySQLProxySession}
* 1. 前端链接器 {@link io.mycat.proxy.handler.MycatHandler,}
* 2. 分析器 {@link MycatClient#analysis(String)}
* 3. 执行器 {@link io.mycat.Command}
* 4. 后端链接器 {@link io.mycat.upondb.MycatDBClientApi}
*
* @param sql 需要分析的sql
* @return 这些结果的数据集 {1.目标数据源 2.目标库 3.目标表 4.是否开事物 5.是否分片,分片类型 6.执行器 7.上下文的变量}
* 在以下情况被调用
* 链接器的 指令类型为查询时 {@link io.mycat.beans.mysql.MySQLCommandType#COM_QUERY}
* 执行器的 语句执行时 {@link io.mycat.ContextRunner#EXPLAIN}
*/
public Context analysis(String sql) ;
public void useSchema(String schemaName);
public TransactionType getTransactionType();
public void useTransactionType(TransactionType transactionType);
public String getDefaultSchema();
public <T> T getMycatDb();
}




