实现差异
jdk1.7
-
数组 + 数组 + 链表实现 (
数组 + HashMap) -
final Segment[] segments; 会初始化Segment[],不初始化HashEntry[]
jdk1.8
-
数组 + 链表实现 (
HashMap) -
volatile Node[] table; 不初始化Node[]
java1.7的ConcurrentHashMap细节 (数组 + HashMap实现)
1.内部关键字段
final Segment[] segments //让每次操作都落到不同的Segment上,减少并发颗粒度
static class Segment extends ReentrantLock {
volatile HashEntry<K,V>[] table = null;//我(table)实现了Hash表
}
static class HashEntry<K,V> {
final K key;
volatile V value;
final HashEntry<K,V> next;//我用next实现了链表
}
2.知识前提
1. HashEntry[] table是存储用户数据的地方. table是数组, HashEntry是链表
2. HashMap的结构 (数组 + 链表)
数组: HashEntry[] table
链表: HashEntry.next
3. 数组的落点segments[index], 这个index是由hash算法算出来的.
4. Segment继承了锁, 即trylock,lock方法和unlock方法
5. 一旦index落到某个Segment上, 那么这个Segment会被上锁.
3.临界竞争区
1.put触发=为某个段(Segment)初始化赋值时,
segments[index].table = new HashEntry[size];
竞争点: cas + Segment.lock()
时机: segments[index].table == null. 注: 实际代码是用cas判断的
2.put,clear,remove触发=操作某个段的table时,
竞争点: 上锁. Segment.trylock()尝试N次失败后,调用Segment.lock(). 注: N次=单核CPU是1次,否则是64次
时机: hash落点一样时,segments[index]
3.rehash触发=扩容时,
竞争点: 调用rehash方法的前提是已经获得了锁,所以扩容过程中不存在其他线程修改数据
时机: rehash(HashEntry<K,V> node)
3.如何提升并发能力
Segment[].length越大,并发能力越高,
因为落到相同地方(Segment[index])的可能性就越小, 只有落点相同才会lock
并发级别参数(concurrencyLevel)控制着Segment[].length
java1.8的ConcurrentHashMap细节 (数组 + 链表实现)
1.内部关键字段
volatile Node[] table; //用来实现存储
volatile Node[] nextTable; //用来接收扩容期间的查询
static class Node<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Node<K,V> next;
}
2.知识前提
1. HashMap的结构 (数组 + 链表)
数组: Node[] table
链表: Node.next
2. 数组的落点table[index], 这个index是由hash算法算出来的.
3. 查询请求是table[index].find()方法实现的
4. Node的子类有
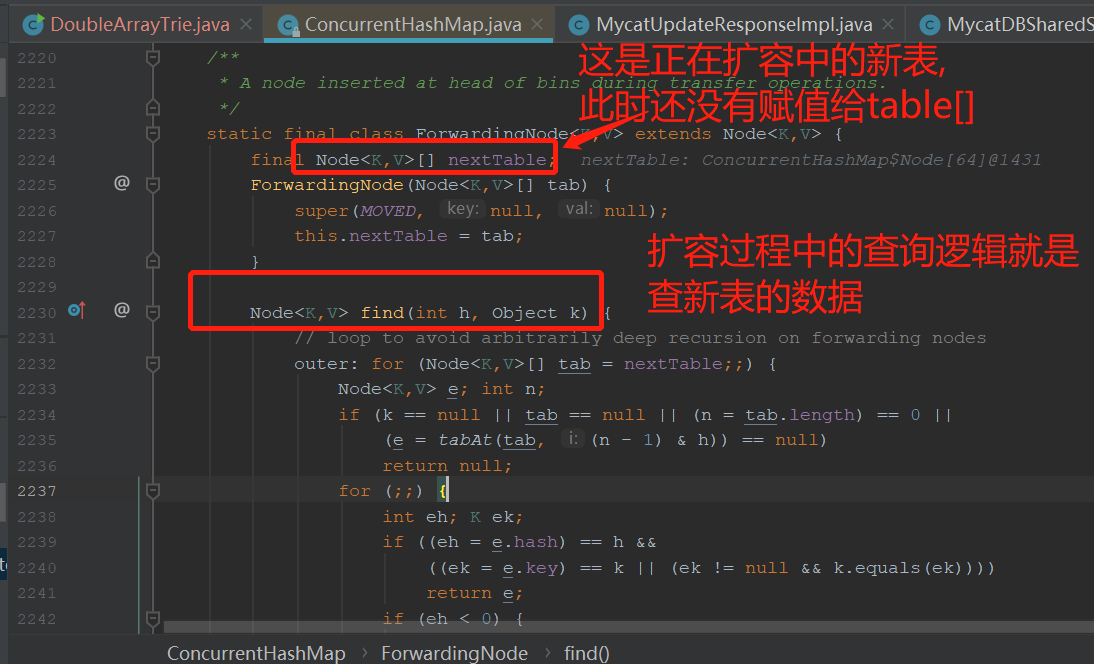
ForwardingNode(扩容期间临时用)
ReservationNode(方法computeIfAbsent或compute时用.这个类的查询find()永远返回null)
TreeBin,TreeNode (链表长度大于8时用)
3.临界竞争区
1.put触发=初始化表时,
table[] = new Node[32];
竞争点: cas + cas失败会Thread.yield直到成功
时机: table等于null时
2.put触发=存储数据时(初始化节点),
table[i] = new Node;
竞争点: cas无线重试
时机: table[i]等于null时
2.put触发=存储数据时(拉链表),
table[i].next = new Node;
竞争点: synchronized(Node)
时机: hash落点一样时,table[index]
3.put触发=树化时,
table[i] = new TreeBin;
竞争点: synchronized(Node)
时机: table[i].next拉链大于8个的时候,会改为TreeBin
4.put触发=扩容时,
table[i] = new ForwardingNode;
竞争点: synchronized(Node)
时机: 1. Node链表长度达到8,但table[].length却小于64时。
2. (当前size / 当前table[].length) > 负载因子(0.75)
5.clear触发=清空时,
table[i] = null;
竞争点: synchronized(Node)
时机: 方法调用后一定会锁
5.merge触发=赋值时,
table[i].next = new Node;
竞争点: synchronized(Node)
时机: hash落点一样时,table[index]
5.remove触发=删除时,
table[i].next = pred.next; (移除链表引用)
竞争点: synchronized(Node)
时机: hash落点一样时,table[index]
6.其他增删改操作时
竞争点: synchronized(Node)
时机: hash落点一样时,table[index]
补充: 在多线程增删改时,
如果当前Node状态是正在扩容,则会帮助这个Node迁移数据(调用helpTransfer方法).
4.树化后的结构如下
table[i] = new TreeBin(new TreeNode());
TreeNode(parent)
TreeNode(我)
TreeNode(left) TreeNode(right)
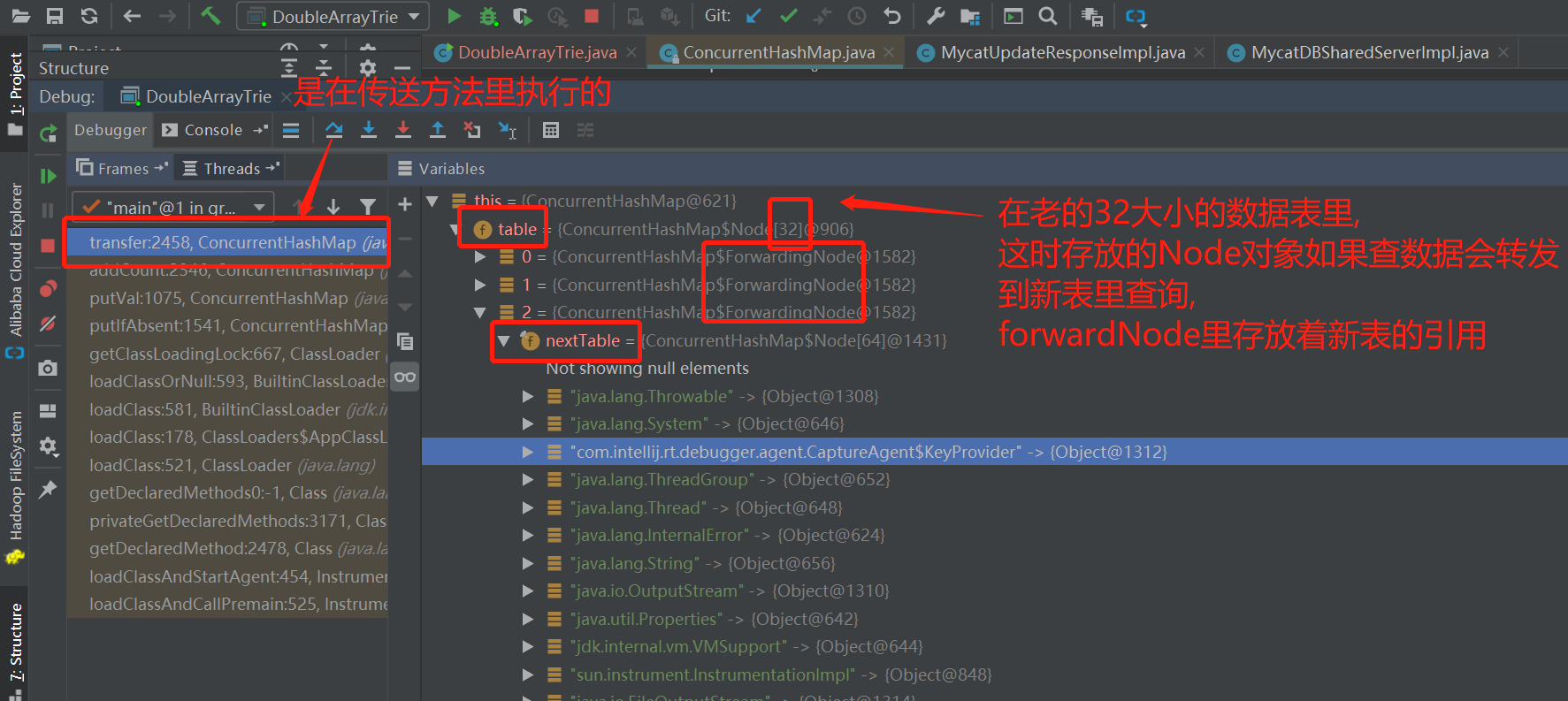
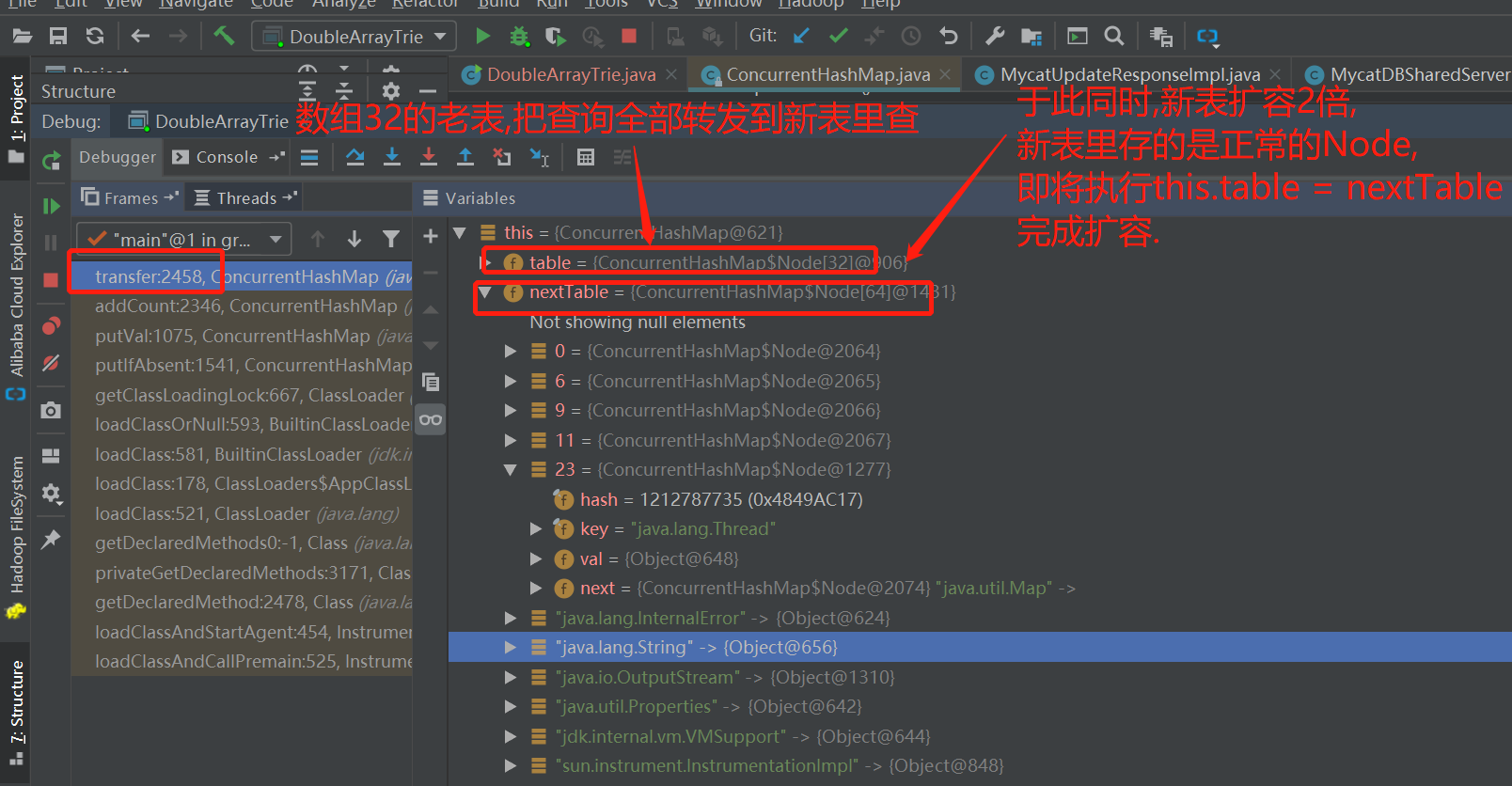
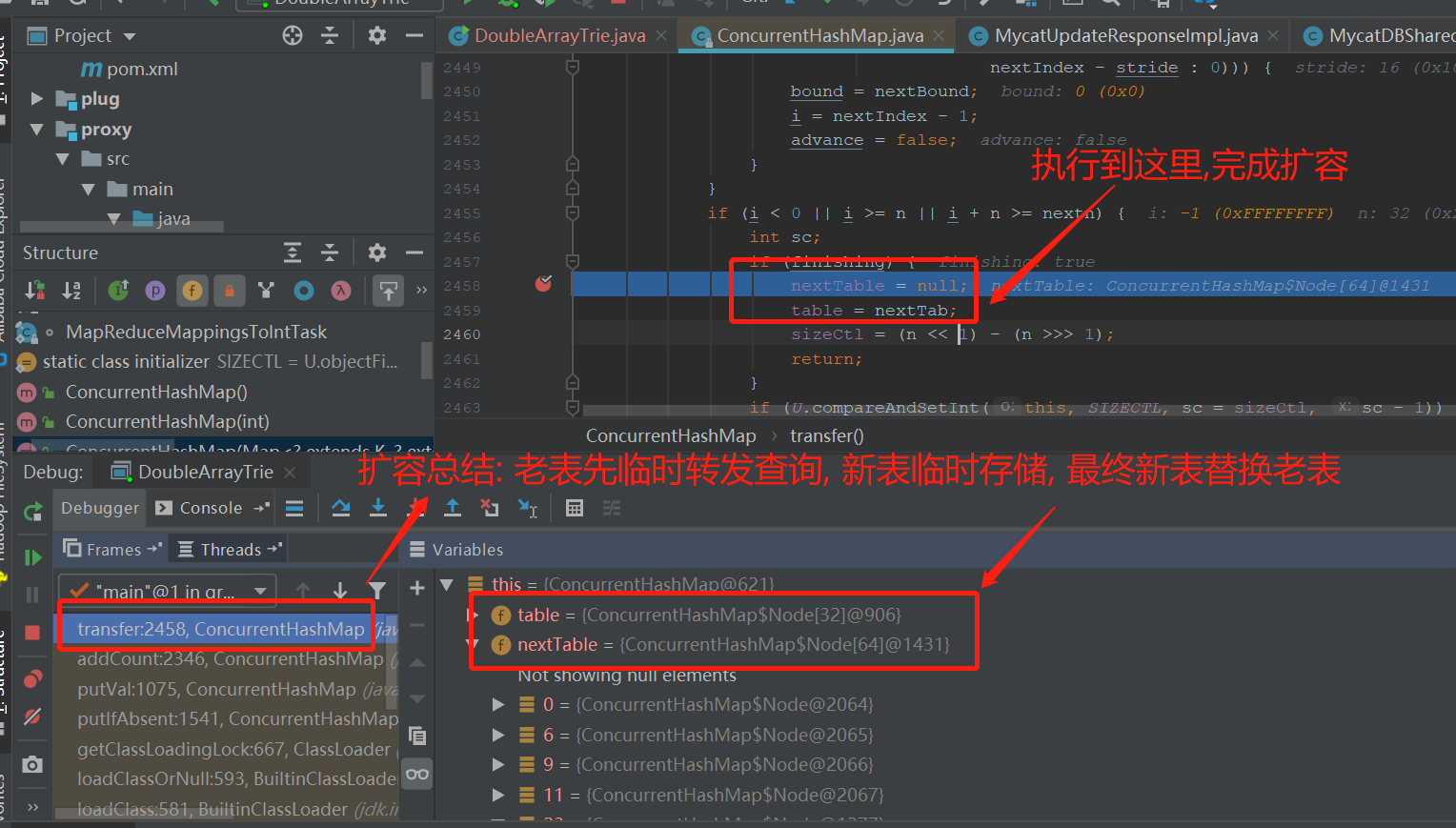
5.扩容伪代码如下
说明: 查询请求是由table[]的Node.find()方法处理的.
扩容前: nextTable[index] = table[index];
table[index] = new ForwardingNode(nextTable);
ForwardingNode重写了find()方法, 如果遇到查询请求,会查nextTable表.
扩容后: this.table = nextTable;