
G1有三种垃圾回收策略(1.年轻代gc, 2.混合gc, 3. full gc是单线程老年代gc)
young gc
触发:
伊甸园区域满了
执行
复制算法. (不会暂停应用)
mixed gc
触发
老年代占整个堆大小超过这个参数.-XX:InitiatingHeapOccupancyPercent=45%
执行
1. initial mark: 初始标记过程,整个过程STW,标记了从GC Root可达的对象
2. concurrent marking: 并发标记过程,整个过程gc collector线程与应用线程可以并行执行,标记出GC Root可达对象衍生出去的存活对象,并收集各个Region的存活对象信息
3. remark: 最终标记过程,整个过程STW,标记出那些在并发标记过程中遗漏的,或者内部引用发生变化的对象
4. clean up: 垃圾清除过程,如果发现一个Region中没有存活对象,则把该Region加入到空闲列表中
full gc
触发
对象内存分配速度过快,mixed gc来不及回收,导致老年代被填满,就会触发一次full gc,
执行
G1的full gc算法就是单线程执行的serial old gc,会导致异常长时间的暂停时间,
需要尽可能的压低-XX:InitiatingHeapOccupancyPercent=45%这个参数, 提前触发mixed gc,
尽可能的避免full gc.
1.线上阿里云频繁报警
<img src="../../../images/postimg/gc2-email.png" width = "200" height = "200" alt="gc2-email" align=center />
<img src="../../../images/postimg/gc2-phone.png" width = "200" height = "200" alt="gc2-phone" align=center />
2.报错信息是full gc超时2秒,导致系统整体卡顿.
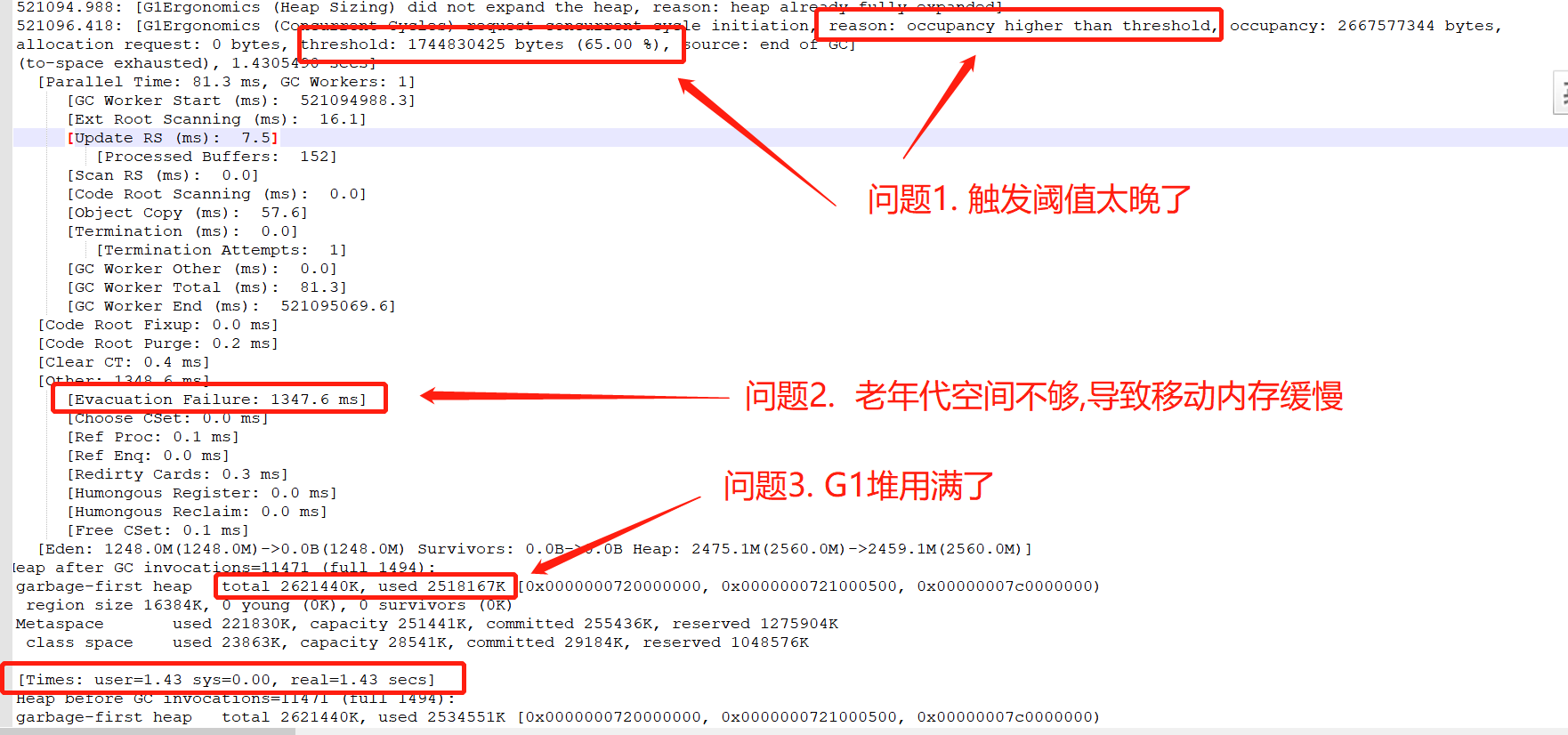
下载gc文件, 找到了这个信息, 耗时1秒多 [Evacuation Failure: 1346.6 ms]
3.百度查了下, 解释如下
Evacuation Failure
当没有更多的空闲region被提升到老一代或者复制到幸存空间时,并且由于堆已经达到最大值,堆不能扩展,从而发生Evacuation Failure。对于G1 GC,它是非常耗时的。
a.对于成功复制的对象,G1需要更新引用,并且该region被一直引用。
b.对于未成功复制的对象,G1将自动转发它们,并保留这些region。
解决方案:
①.不要过度加一些jvm参数。比如-Xmn,这个参数会限制G1的参数的自动扩展。可以仅使用-Xms,-Xmx和暂停时间目标-XX:MaxGCPauseMillis,删除任何额外的堆大小,例如-Xmn,-XX:NewSize,-XX:MaxNewSize,-XX:SurvivorRatio等。
②.如果问题仍然存在,则增加JVM堆大小(即-Xmx)。
③.如果您无法增加堆大小,并且您注意到marking cycle没有足够早地开始回收老一代,那么请减少-XX:InitiatingHeapOccupancyPercent。默认值是45%。减小该值将提前开始marking cycle 。另一方面,如果marking cycle 提前开始并且未收回,请将-XX:InitiatingHeapOccupancyPercent阈值增加到默认值以上。
④.如果并发marking cycle准时开始,但需要很长时间才能完成,那么使用属性'-XX:ConcGCThreads'增加并发标记线程数的数量。默认是GC Workers: 1 ,单线程执行。
⑤.如果有大量“空间耗尽(to-space exhausted)”或“空间溢出(to-space overflow)”GC事件,则增加-XX:G1ReservePercent。默认值是Java堆的10%。注意:G1 GC将此值限制在50%以内。
4.寻找大内存触发根源.
1. 原来是导出excel占用内存过多, 以前为了开发方便着急上线(没有预估数据量), 直接把日期范围的数据全部
查询了出来进行导出, 导致老年代不够用
5.复现问题.
我尝试一次性导出2W+条数据, 果然就收到GC超时报警了.
6.解决问题.
现在改程序还要开发测试上线, 时间太久. 我决定先改JVM参数解决问题.
总结出问题: 1.老年代不够了 2.老年代没有被提早回收,导致暂停时间过久
G1会自动调整逻辑代的大小, 基本不需要人工参与.配置上老年代新生代的内存会抑制G1自动调整.
G1可以用分代的参数去配置, 但它的内存模型是不区分代的.
当分配大内存的时候, G1就可以自动调整老年代.
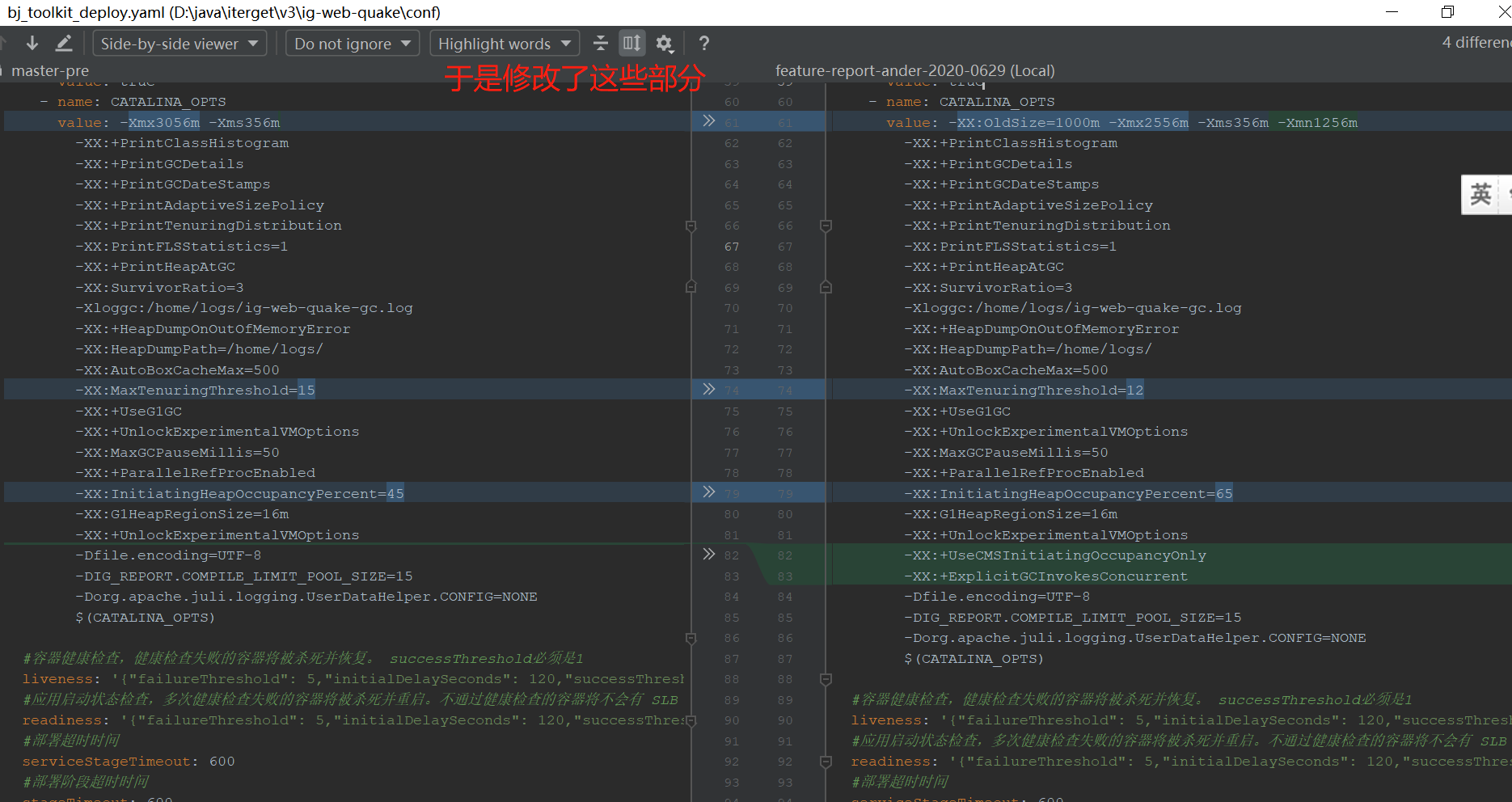
我赶紧检查一下项目的启动参数, 并进行了修改
1. 去掉了新生代和老年代的参数限制(Xmn,OldSize), 只控制整个堆的最大内存和初始内存. 年轻老年代自动调整.
2. 以及堆占比进行GC阈值的参数改为了 33%(InitiatingHeapOccupancyPercent), 让提前进行回收.
7.上线 (问题解决)
我再次大批量导出2W+条数据, 就不再提示报警了.
后续要把代码改成流式写入excel, 然后用DeferredResult进行异步导出.




