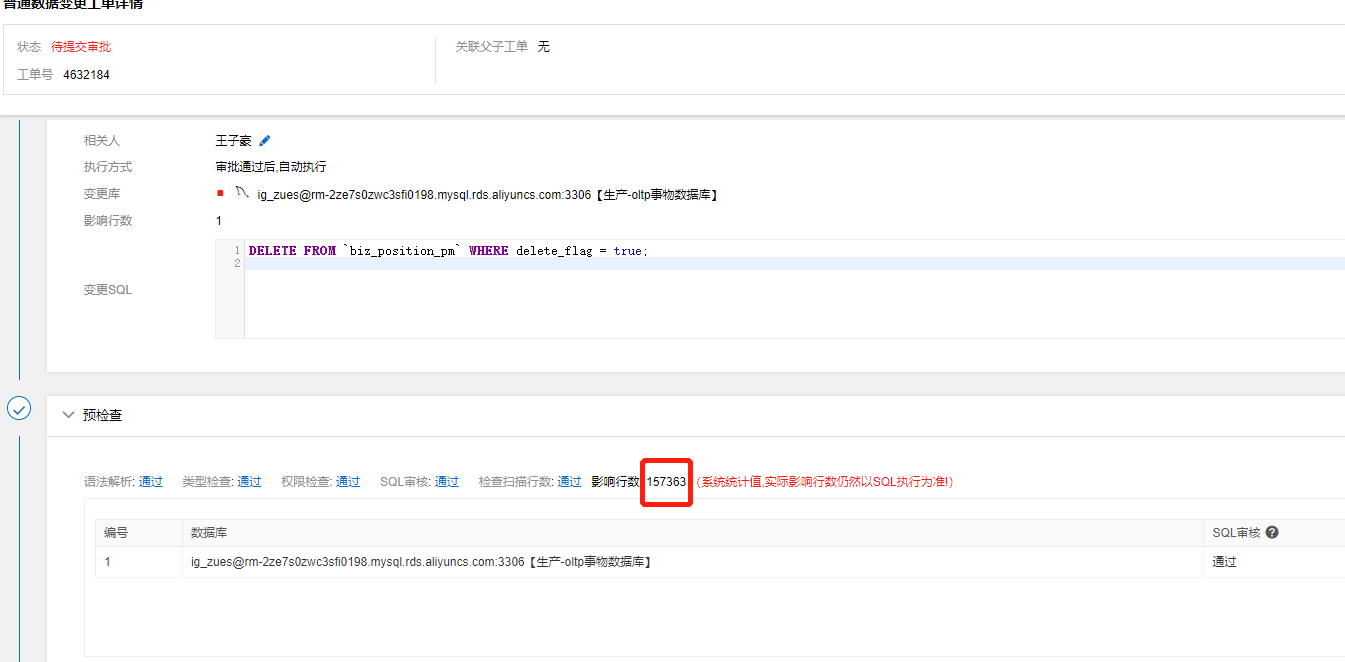
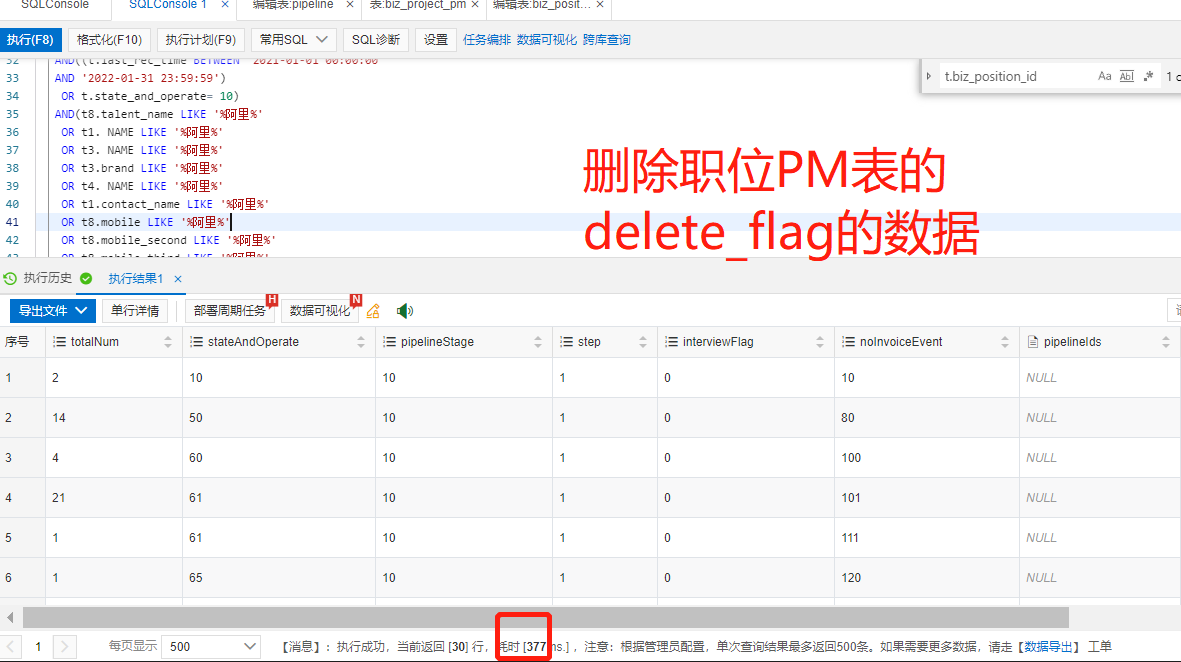
1. 关联关系表(用户点全选,保存。 每次都是先全删在增。用户编辑的代价非常小,所以数据增长很快)
2. EXISTS 或 IN 会导致选择外圈驱动表失效, 尽量用left join 或inner join。
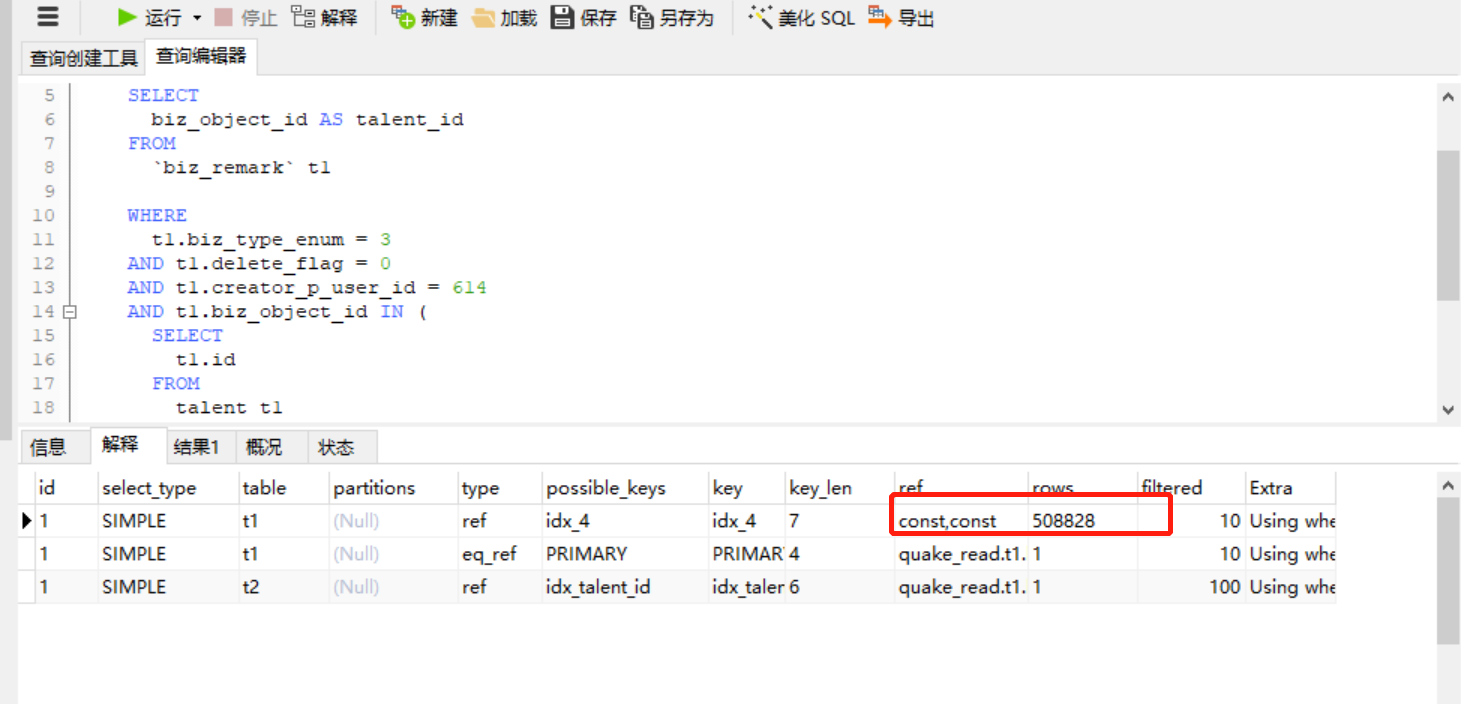
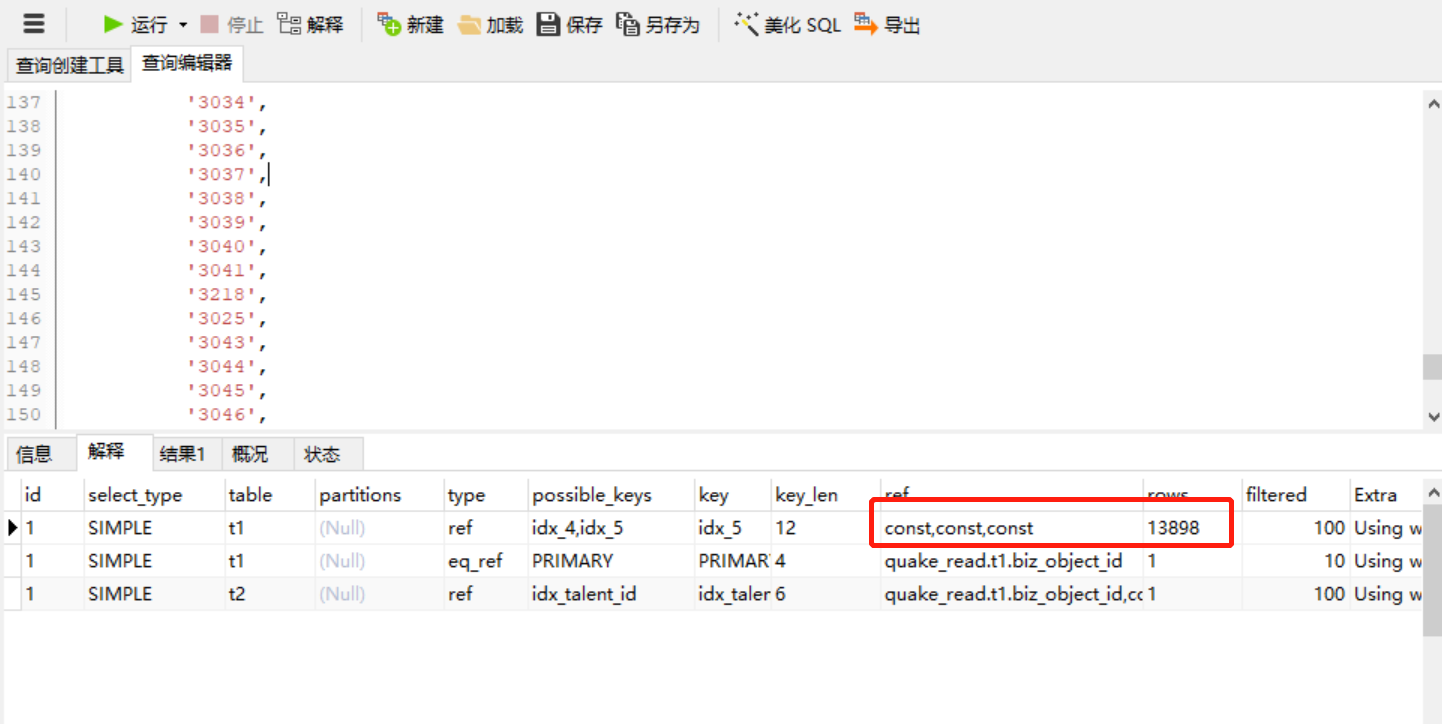
3. 联合索引 , 使sql满足ref的满字段的const(ref = const,const,const)
4. 不用的数据需要归档,审批提醒,周报提醒,待办提醒等. 冷热数据分离
这个服务没有特殊逻辑, 就是增删改查。
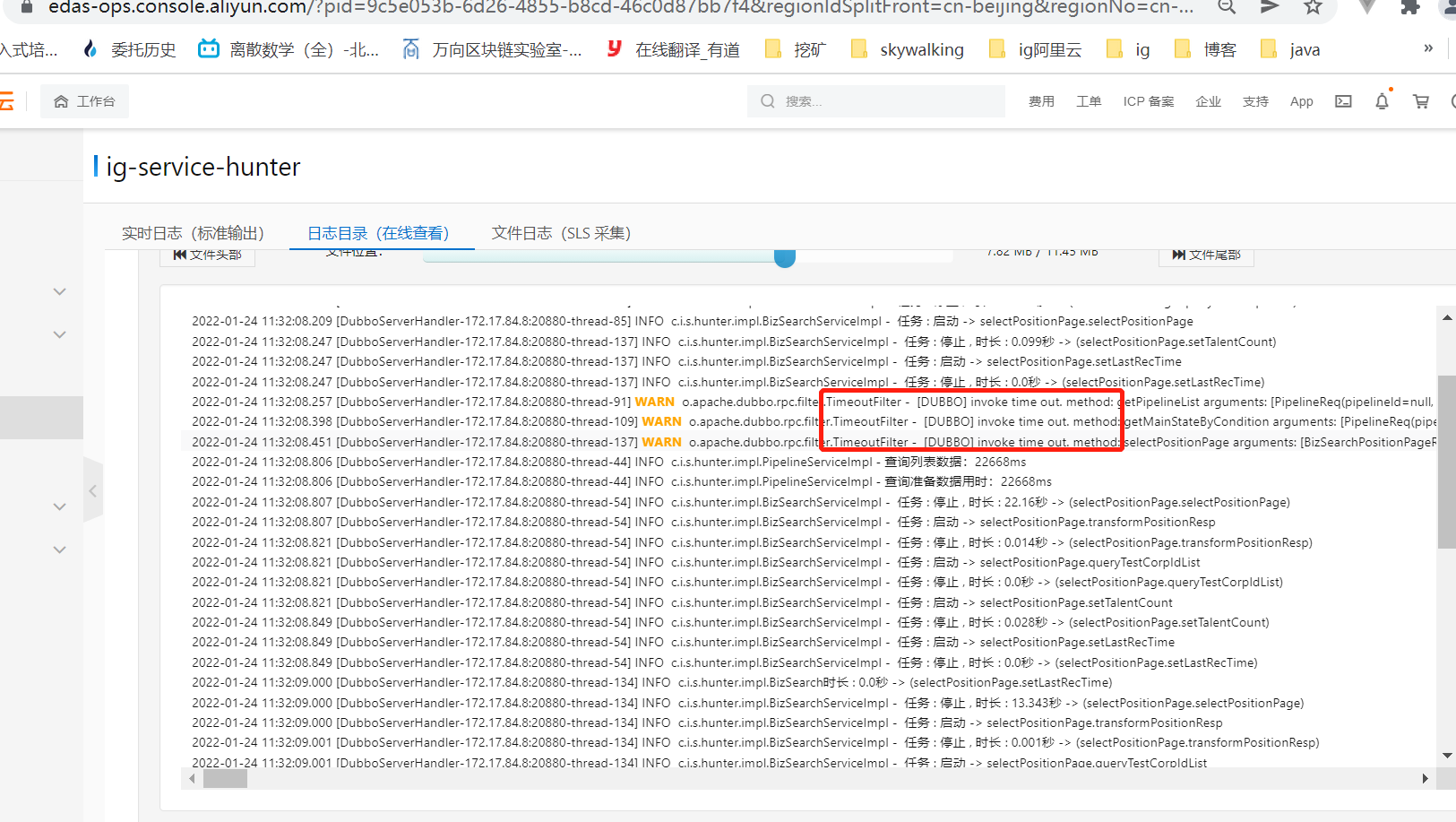
每个服务只能做增删改查, 员工人数不多,正常不会高并发增删改,接口记录里也没有多少个增删改。
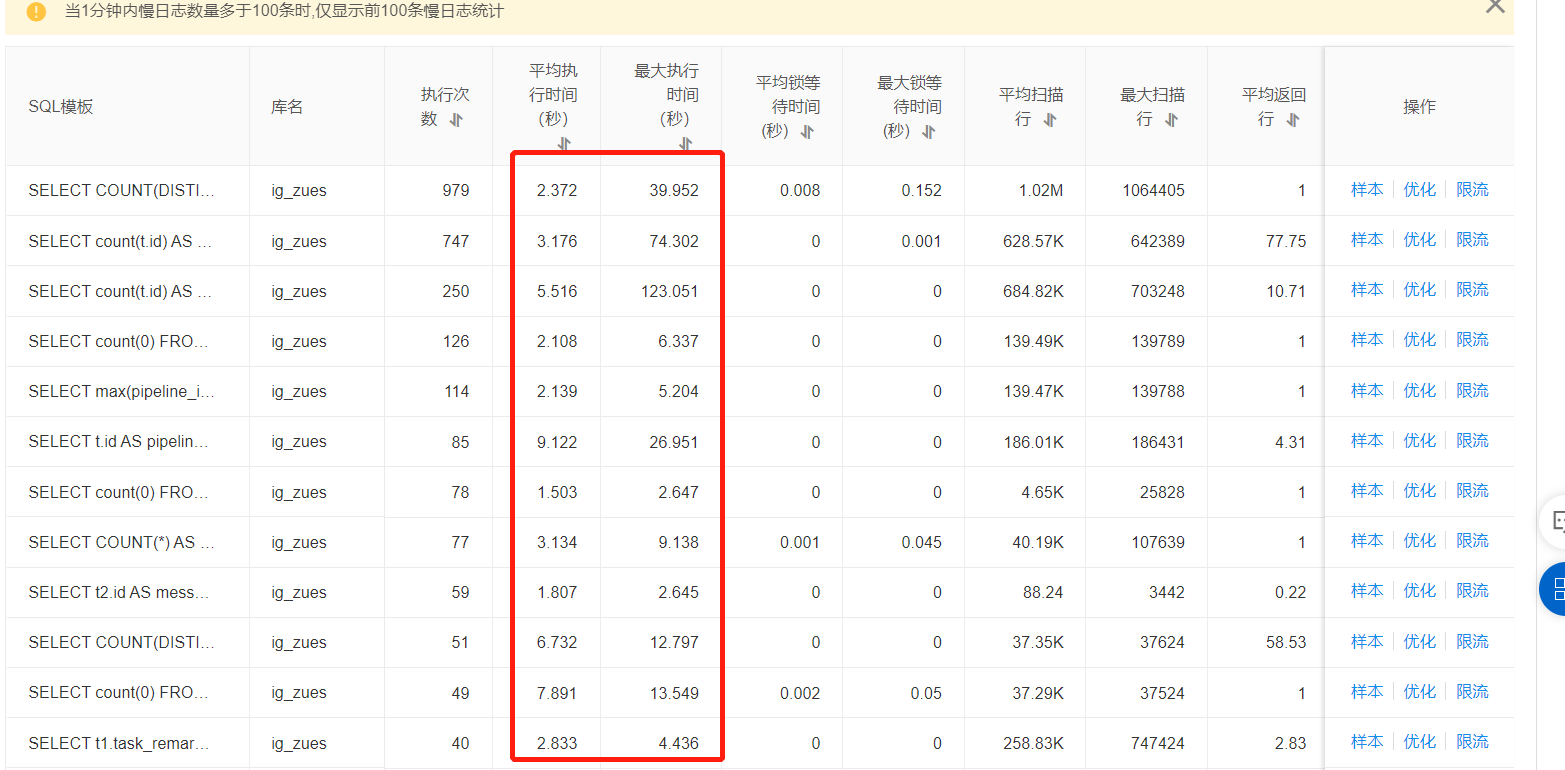
相比之下,查询导致线程池满的可能比较大。
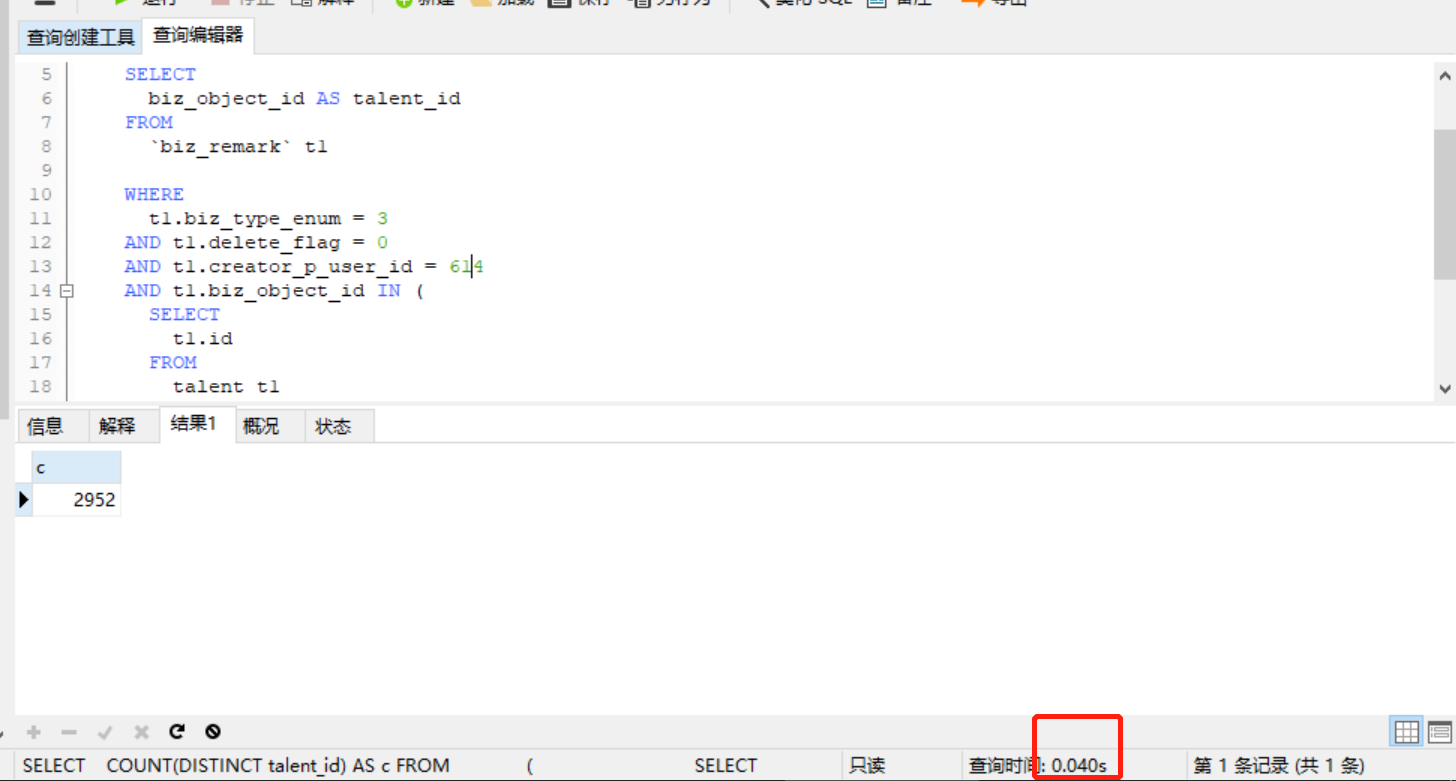
见下图
改之后的索引
ALTER TABLE `biz_remark`
ADD KEY `idx_5`(`delete_flag`,`biz_type_enum`,`creator_p_user_id`,`biz_object_id`);
改之前的索引
ALTER TABLE `biz_remark`
ADD KEY `idx_5`(`delete_flag`,`biz_type_enum`,`biz_object_id`, creator_p_user_id);
可以走3个字段联合: [user_id, user_type, product_id]
可以走最数据少的那个字段: [user_id, user_type] [product_id]
因为mysql5.67之前索引只能选一个, 预测过滤后数据最少的那个索引(覆盖字段越多,回表代价),选择用那个索引。
5.67之后可以走index_merge